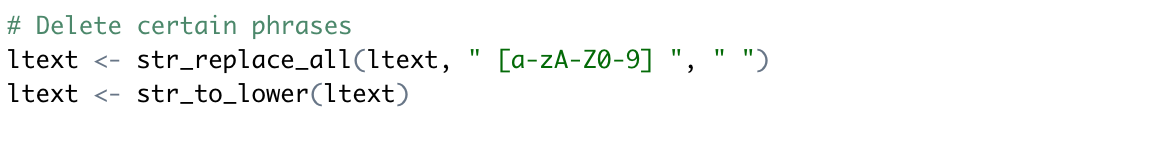Section 5.5 Textualizing the Data
Motivating Ideas.
In this section, I will...
Understand the definition and process of text analysis.
Know how to clean data for text analysis.
Know how to create qualitative visualizations.
Understand how to use text analysis to interpret legislation.
Subsection 5.5.1 Cleaning for Text Analysis
Text analysis is the process of using computer systems to understand human-written text for analysis purposes including analyzing legislation. Text can be analyzed from unstructured data sources such as emails, surveys, documents, and other online material to extract insights. The main feature of text analysis is training computer software to associate words with meanings, similar to how humans learn a new language through objects, actions, and emotions. Deep learning and natural language processing (NLP) are the principles of text analysis.
(Source). 115
In this chapter, you will explore anti-trans legislation through text analysis. Note, this approach requires additional cleaning. This cleaning process depends on the specific bill, its formatting, and your group’s preferences. Decisions must be made about how much you want to clean the data for your specific project.
Note: whenever you download a file to open in R or R Studio, make sure to set your working directory to wherever that file is located. For example, if you have the file just on your desktop (not in any folder), entering “setwd("~/Desktop")” in the console window will set the working directory to your desktop.
Activity 17.
Before we do any text analysis, we have to do some data cleaning. We will use an Arizona bill regarding trans legislation as an example, which can be viewed
here 116 .
After downloading the "4-bill-test" excel file, we can enter the following code in R:
This will install some necessary packages for cleaning and read the excel file into R. We want to look at first anti-trans bill in the excel file- an Arizona bill vetoed that addresses pronoun use in schools. Add the following code below what you already have:
This code will output the first row of text of the bills file. We will now clean this section with the following code. Run each block one at a time along with the code from above. You can enter "ltext" at any point to check your progress.
-
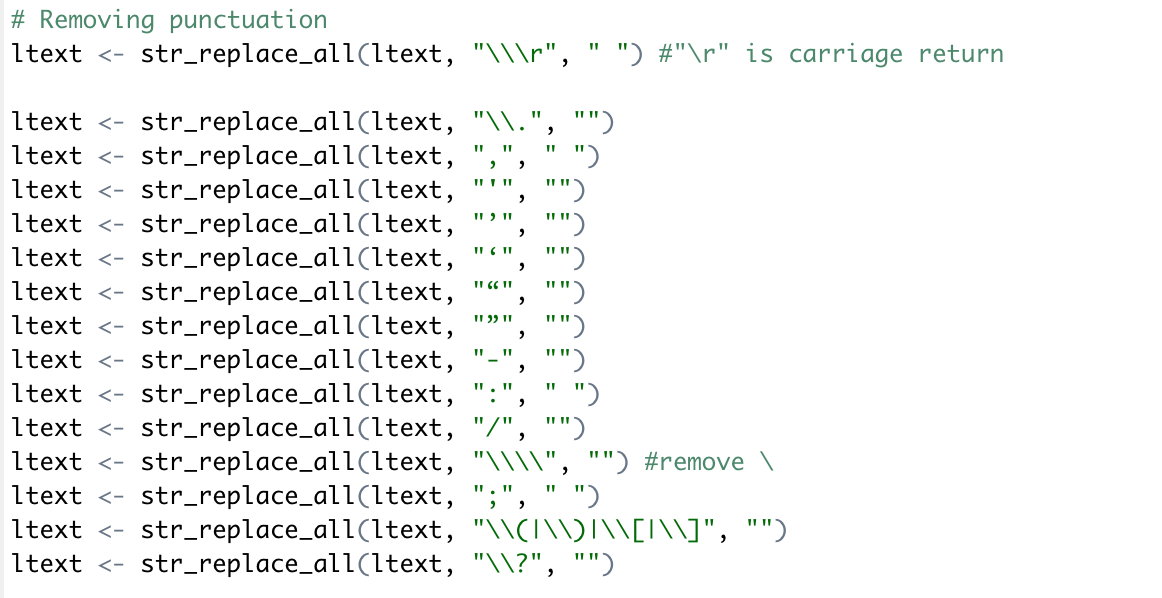
Removing line breaks.
-
Deleting punctuation.
-
Deleting a phrase or line.
This text tends to have a 1. and a. and (a) and (b). We already eliminated parentheses and periods, so now we are going to eliminate all single letter words and numbers. We are intentionally not removing all numbers. There are several references to K12 or under 18 so we want to maintain these. We also want to make sure that our words will be recognized as the same when we construct relationships, so we have to convert everything to lowercase.
-
Removing redundant spaces.
-
Identifying and eliminating stop words.
Stop words are common words that carry little textual meaning, so we do not need to include them in our analysis. For example, "the", "are", "is", etc...
After cleaning the data, a block of text remains.
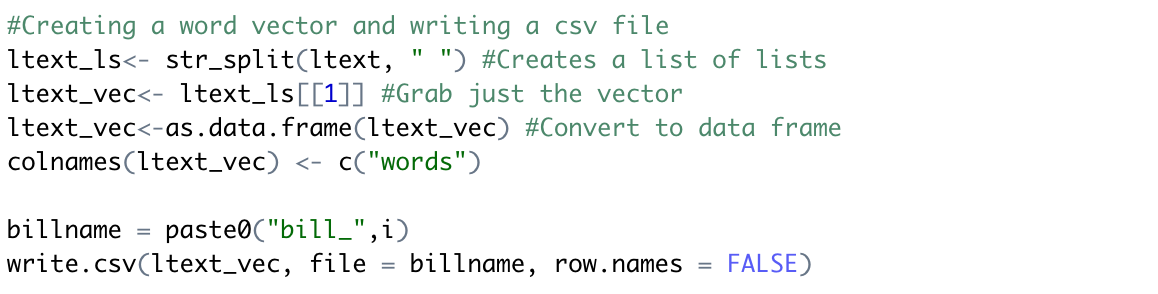
In order to analyze the block of text, we need to get these words into what is called a word vector. For those unfamiliar with the idea of vectors, word vectors are a list of words, with one word on each line. If you are familiar with vectors from other math courses, the idea of a word vector is similar: it is a list of words in an array format. We can create a word vector and save it as a new csv file with the following code:
You can enter "ltext_vec" to view our word vector. Play with the following code to analyze your text.
We can note that the relative frequency (rflel) is the number of times a particular value for a variable has been observed in relation to the total number of values for that variable. We can also see from our top 20 list that "school" and "pronoun" were of the most common words used in the text. This makes sense given the context of this bill.
Subsection 5.5.2 Visualizing Text Analysis Data
We can continue our investigation of the bill by creating and analyzing visualizations.
Activity 18.
Open atl_heritage.Rmd in R Studio and run the code by selecting Run→Run All. A small yellow banner may pop up at the top of your screen that you do not have a library installed. Press “Install,” and run the code again.
Tabs named “bills,” “template_leg,” “probills,” “ltext_cuonts,” and “counts_ordered” appear in the bar next to the original .Rmd file. What information do each of these tabs contain?
After running the code, some tables and graphs will appear directly in the code. Return to the .Rmd tab and scroll through the code until you find the following table. How many times does the word “employee” appear in the bill? Hint: look at the “n” column. What is the relative frequency of the word “education”? Hint: look at the “relf” column.
Continue to scroll through the graphs. Talk with a partner about what looks nice in each graph, and what you would want to change. Which graph is your favorite? Why?
Subsection 5.5.3 Exercises
Now, it’s your turn to try!
Checkpoint 5.5.1.
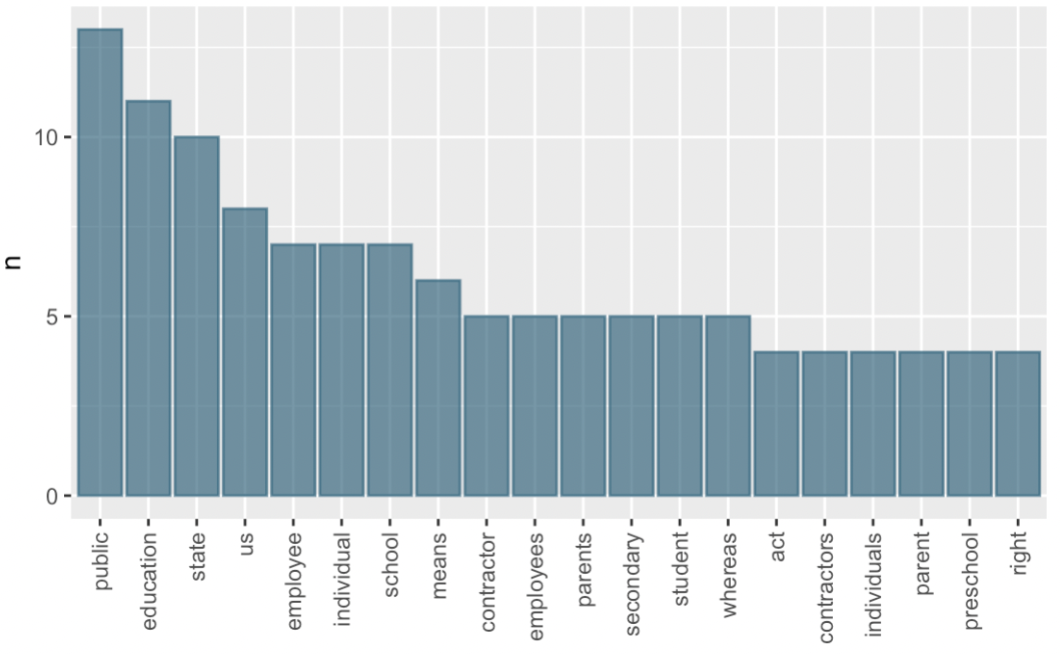
Using the following graph, answer the questions 1-6.
What does the label “n” on the y-axis mean?
What title would you give to the graph?
How many words appear exactly 5 times in the bill?
How many words appear at least 7 times in the bill?
What word appears the most?
What might this information tell us about the bill?
Checkpoint 5.5.2.
List 3 things you can do to clean data learned in Section 5.4 and 3 things you can do to clean data for text analysis (discussed in this section). What are some similarities and differences between the methods you came up with?
Checkpoint 5.5.3.
What do you think would happen if you didn’t clean the data before making a word vector? How might the graph look different?
Checkpoint 5.5.4.
Which cleaning method for text analysis do you think would be most useful to learn? Why? This question is asking for an opinion, there is no right answer.
aws.amazon.com/what-is/text-analysis/
github.com/DAAAAMNSocialJustice/anti-trans-legislation/blob/3f450de86643b58c20df51e910cf7ebd8c4a266e/4-bill-test.xlsx
github.com/DAAAAMNSocialJustice/anti-trans-legislation/blob/3f450de86643b58c20df51e910cf7ebd8c4a266e/atl_heritage.Rmd
github.com/DAAAAMNSocialJustice/anti-trans-legislation/blob/3f450de86643b58c20df51e910cf7ebd8c4a266e/4-bill-test.xlsx
github.com/DAAAAMNSocialJustice/anti-trans-legislation/blob/3f450de86643b58c20df51e910cf7ebd8c4a266e/template%20legislation.xlsx
github.com/DAAAAMNSocialJustice/anti-trans-legislation/blob/3f450de86643b58c20df51e910cf7ebd8c4a266e/Pro-LGBTQ-Bills.csv
github.com/DAAAAMNSocialJustice/anti-trans-legislation